DNA
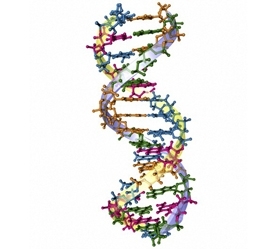
Deoxyribonucleic acid (DNA) is a long chain organic molecule that contains the coding for all metabolic and reproductive processes of all living organisms, save for certain viruses. This helix shaped molecule consists of a spine that contains a sequence of nucleotides, whose order comprise the coding instruction for each specific lifeform. DNA itself is not alive, but holds the instruction set for building a vast array of proteins as well as its own replication. By governing the synthesis of proteins, DNA is inherently the key substance for the maintenance and replication of every cell in nature, as well as DNA-containing viruses that subsist in another organism's host cells. Most DNA is contained in cell nuclei except for mitochondrial DNA—this is contained in cell organelles or chloroplasts.
A single DNA molecule contains all the information required to assemble any complete organism; in fact, the macro-structure of circular versus linear DNA geometry distinguishes biological domains (e.g. prokaryote versus eukaryote). The unique coding of the DNA sequence defines every distinguishing attribute of a species, as well as the uniqueness of an individual within its species.
Contents
Structure
DNA, of course, is not a single well defined molecule, but can occur in an enormous number of different codings, since, by its nature, any given DNA molecule contains the complete instruction set for an entire species. The structural properties inherent in any DNA helix are the backbone of a pentose sugar and phosphate residue, with one of four bases attached to a carbon atom of each sugar. The width of a single DNA molecule is approximately 22 to 26 Angstroms and the length of one repeating nucleotide chain link (phosphate, sugar, base) is about 3.4 Angstroms. Around 10.4 nucleotide units are required to complete one full twist of the DNA helix. DNA usually occurs as helical linear coiled form in eukaryotes, and circular chromosomes in prokaryotes; these forms are both helices, but the prokaryotic form has its ends attached to form a complete looping structure. One large distinction between DNA and RNA is the sugar, with the 2-deoxyribose in DNA being represented in RNA by merely ribose.
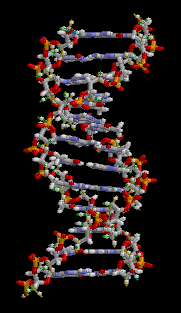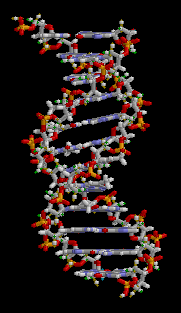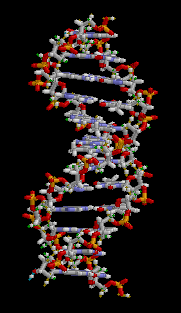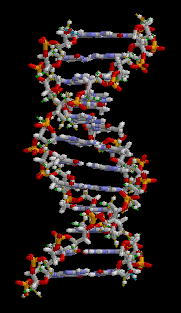
The double helix
In living cells DNA typically occurs as a double helix where two compatible helical coils are intertwined and the bases are held together with hydrogen bonds. The four bases that are inherent in DNA definition for life on Earth are Guanine (G), Cytosine (C), Adenine (A) and Thymine (T). Importantly, hydrogen bonding in the double stranded DNA pair occurs only between the A and T or G and C base pairs. In double helix form, this intertwined coil of two hydrogen bonded DNA molecules is termed a chromosome. For example, the length of this entire polymeric molecule occurring as the longest of the human chromosomes is approximately 220 million nucleotide lengths or a staggering seven centimeters long; however, this molecule in practice never occurs so stretched out, but is inherently coiled and, in fact, full of kinks, such that this long slender kinky molecule has a maximum dimension of only a minute fraction of its uncoiled hypothetical length.
Sense and anti-sense strands
The DNA double helix contains two long helical molecules, that are chemically mirror images, since the opposing bases are A or T, or G or C, respectively. However, their coding and signally properties are quite different. In fact, the anti-sense strand is the strand of DNA transcribed into messenger RNA (mRNA). The immediate product of this transcription is called an initial RNA transcript. This product is the same as the sense strand except the nucleotides are RNA instead of DNA, and the base uracil is substituted for thymine. Strictly speaking, only the mRNA makes "sense" with the genetic code as the translated protein peptide sequence can be directly deduced from this strand. The anti-sense strand is complementary to the sense strand and is the real template for mRNA synthesis.
Asymmetry of strand ends
The two ends of the linear helical DNA structure are inherently different. The sugar in DNA is 2-deoxyribose, a five-carbon molecule. Along the DNA backbone, sugars are joined via phosphates that form phosphodiester bonds (between carbon atoms three and five)p of adjacent sugar rings. These asymmetric covalent bonds dictate that a strand of DNA has a direction. In a double helix the direction of the nucleotides in one strand is opposite to the directionality of the complementary strand. The asymmetric ends of DNA strands are called the five prime (5') and three prime (3') ends; the 5' end terminates in a phosphate group, and the 3' end terminates in a hydroxyl group.
Supercoiling
DNA can be over-twisted like a rope in a phenomenon termed supercoiling. In a relaxed state, a strand usually circles the axis of the double helix about once every 10.4 base pairs, but if the DNA is twisted (or untwisted) the strands become more tightly (or more loosely) wound. DNA over-twisted in the direction of the helix is positive supercoiling, and the bases are held more tightly together. Untwisting is called negative supercoiling, and the bases come apart more easily. In nature, DNA has subtle negative supercoiling caused by enzymes known as topoisomerases.These molecules are used to relieve the twisting stresses introduced into DNA strands during replication and transcription processes.
Coding and replication
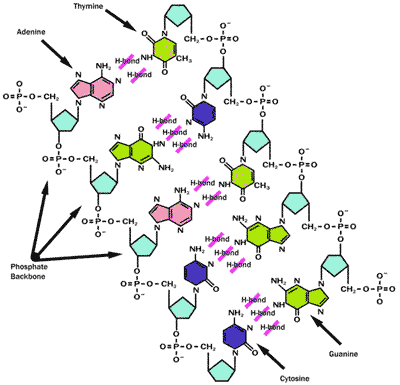
DNA carries the fundamental coding instructions for not only genetic replication of an organism, but also the instruction set for vital protein biosynthesis within cells. In other words, the DNA molecule possesses all the information required for cell division, genetic inheritance and also serves as an instruction manual for the cell's most complex functions of protein manufacture. Replication is the process wherein the double stranded helix uncoils to yield two molecular "mirror image" base pair complementary DNA single strands, each of which proceed to create its new mirror image strand of DNA.
Coding
The sequence in base pairs provides the coding instructions for protein biosynthesis. It has been determined that a sequence of three nucleotides is the code related to produce or add a specific amino acid to larger molecules. Some of these amino acids can be synthesized by an organism, and others must be ingested, leading to the term essential nutrient.
Since there are only three bases in the fundamental codon, with a choice of four different bases (A, T, C, G), there are a total of exactly 64 codons, each sequence of which is associated with a specific amino acid. Several codon sequences may code for the same amino acid; for example, the codons TCA, TCC, TCT, TCG all code for the amino acid serine. The sequence ATG has special significance in that it codes for the amino acid methionine, but also serves as the single signal for the beginning of every protein sequence. There are three codons that signal the stop position of protein formation: TAA, TGA and TAG. These stop sequences ensure that the protein created has the precise number of amino acids required, and that each protein has a clear end point in its amino acid chain.
Replication
As an intrinsic part of cell division the nuclear DNA must be replicated such that the two daughter cells end up with the same genetic coding as the parent cell. The double-stranded structure of DNA provides a canonical mechanism for DNA replication. The two strands separate or melt, after which each strand complementary DNA sequence (or base pair molecular image) is recreated via action by DNA polymerase, an enzyme that manufactures the mirror strand by locating each proper mirror base, and bonding it onto the original entire strand.
DNA replication processes begin with the melting apart or separation of the two complementary strands. The mysteries of signalling that command the timing of DNA double strand melting are being actively researched. What we do know is that DNA strands melt or with small temperature increases at highly localized regions along the DNA base paired hydrogen bonds. The thermal impetus for melting arises from energy released by localized ATP hydrolysis. As DePamphilis points out, the subsequent mechanisms in different organisms and within the nuclear and mitochondrial realms pose a "bewildering array" of complex mechanisms for replication.
Typically the replication process is incepted at one or more distinct sites along the DNA molecule, often termed origins of replication. The strand opening process is caused by localized negative supercoiling and or presence of specific initiator proteins. Next a DNA helicase (enzyme that utilize ATP hydrolysis energy) is loaded onto the exposed single strand. Some helicases work in a 3' to 5' sense and others work in the opposite direction.
The most critical step in replication is the insertion of a short RNA strand at the origin of replication site; DNA polymeras cannot start its task of replication without this primer activity. The need for this RNA primer is almost universal within all organisms, in both nuclear and mitochondrial DNA, with the exception of some n such as certain parvoviruses. Once the RNA primer is attached a DNA polymerase can go to work with the rest of the chain replication; these polymerases not only can replicate very long chain base pairing, but have a capability of "proofreading" such that mistakes in matching pairs are discarded. This quality control is very important in insuring faithful propagation of species and minimization of mutations.
Role in cellular biology
DNA in cell nuclei and in mitochondria provide the entirety of coding for the cell metabolism as well as the procreation of new cells. In fact, the DNA present in any given cell of an organism contains all the genetic information to code for all body metabolism and all characteristics of the entire organism!
The fundamental process of cell division is intimately associated with the unzipping of the double stranded helix within the cell nucleus. Each strand can then replicate itself by attachment of the corresponding base pair at each nuclotide site of the unziapped single strand DNA. The other basic function of DNA within cells is to provide the coding instructions for cell manufacture of proteins.
Mitosis

The genetic information in a genome is held within genes, and the complete set of this information in an organism is called its genotype, contained in the chromosomes within the cell. Upon mitosis, or cell division, complete replicas must be made of the original chromosomes, or entire DNA set of a parent cell. The human chromosome set omA gene is a unit of heredity and is a region of DNA that influences a particular characteristic in an organism. Genes contain an open reading frame that can be transcribed, as well as regulatory sequences such as promoters and enhancers, which control the transcription of the open reading frame.
In most species merely a small fraction of the total sequence of the genome encodes protein. For example, only about 1.5% of the human genome consists of protein-coding sequences. It remains unclear why so much of the DNA molecule holds no useful information; some have suggested that such unused sequences are genetic fossils, or remnants of prior organism traits, that have been terminated by evolution as genetic traits that previously existed, but at some time point ceased to prove useful in survival.
Protein coding
In transcription, the DNA codons are copied into messenger RNA using RNA polymerase. This RNA copy is then decoded via a ribosome that reads the RNA sequence by base-pairing the messenger RNA to transfer RNA, which carries amino acids. This process of cell biosynthesis is vital to organisms, since (i) these proteins are essential to cell function and division; and (ii) the proteins produced are not usually commonly available from dietary sources available to the organism.
History of Research

The earliest isolation of a nucleic acid occurred by Friedrich Miescher in 1863, working with fish sperm and pus cells; however, it was not until the year 1919 that Levene correctly identified the nucleotide unit as comprised by base, sugar and phosphate nucleotide unit. Levene argued that DNA consisted of a string of nucleotide units linked together through the phosphate groups, but he posited that the chain was short and the bases repeated in a fixed order. In 1928 Griffith suggested the molecular transfer of genetic information. Astbury in 1937 was the first to demonstrate X-ray diffraction patterns proving that the DNA strand has a regular structure.
Work of Avery, MacLeod and McCarty in 1943 showed that DNA was implicated in the actual transfer of this genetic coding. In 1952 Hersey and Chase showed that phage DNA carried genetic coding. The most heralded part of the discovery saga was the 1953 research of Franklin, Crick, Watson and Wilkins to elucidate the helical structure of the DNA molecule. In 1963 Frick Laboratory at Princeton with researchers Fresco, Klotz, Edwards and Hogan produced the first detailed analysis of messenger RNA structure and its role in DNA replication.
Current events and forensics
There is a vast amount of ongoing research on DNA structures and their role in cellular biology. Notable applications in the past two decades has been the widespread use in criminal forensics, where DNA typing has allowed linkage of individual humans to a crime with high liklihood of certainty. Many sample analysis outcomes have been able to make this linkage within a possible error of approximately once chance per billion.
There is extensive research being conducted on the role of DNA mutations as a cancer precursor and developing methods of intervention for carcinoma progression. Other forms of research are progressing on DNA fossil analysis and genome mapping that allow production of cladistic relationships that illuminate evolutionary origin and connections of related taxa. These regression analyses lead to hypothetical cladistic diagrams showing the likely relations of taxa common ancestors and provisional dating of ancestral linkages. Of a more controversial nature is gene splicing research, where new organisms may be created for enhanced crop yields or other purposes.
References
Structure
- J.Watson and F.Crick. 1953. A Structure for Deoxyribose Nucleic Acid" (PDF). Nature 171 (4356): 737–738.
- A.Ghosh and M.Bansal. 2003. A glossary of DNA structures from A to Z. Acta Crystallogr D Biol Crystallogr 59 (Pt 4): 620–6.
Coding and replication
- J.Fresco, L.Klotz and E.Richards. 1963. A New Spectroscopic Approach to the Determination of Helical Secondary Structure in Ribonucleic Acids. Cold Springs Harbor Symposia on quantitative Biology.
- Jacques.Fresco, Lynn.Klotz, E.Richards, C. Michael.Hogan et al. 1963. Polarized Light Spectoscopic Methods of Determining Structure of Messenger RNA. Frick Laboratory. Princeton University.
- J.Bikandi, R.San Millán, A.Rementeria J.Garaizar. 2004. In silico analysis of complete bacterial genomes: PCR, AFLP-PCR, and endonuclease restriction. Bioinformatics [Associated software tool for DNA to protein translation]
- Melvin L DePamphilis 1996. DNA replication in eurkaryotic cells. CSHL Press. 1058 pages
Role in cellular biology
- B.Alberts, A.Johnson, J.Lewis, M.Raff, K.Roberts and P.Walters. 2002. Molecular Biology of the Cell; Fourth Edition. New York and London: Garland Science. ISBN0-8153-3218-1
History of research
- R.Krasner. 2009. The Microbial Challenge: Science, Disease, and Public Health. Jones and Bartlett. 476 pages.
